
Authors:
(1) Gaurav Kolhatkar, SCTR’s Pune Institute of Computer Technology, Pune, India ([email protected]);
(2) Akshit Madan, SCTR’s Pune Institute of Computer Technology, Pune, India ([email protected]);
(3) Nidhi Kowtal, SCTR’s Pune Institute of Computer Technology, Pune, India ([email protected]);
(4) Satyajit Roy, SCTR’s Pune Institute of Computer Technology, Pune, India ([email protected]).
Table of Links
III. METHODOLOGY
A. Stages of our proposed approach
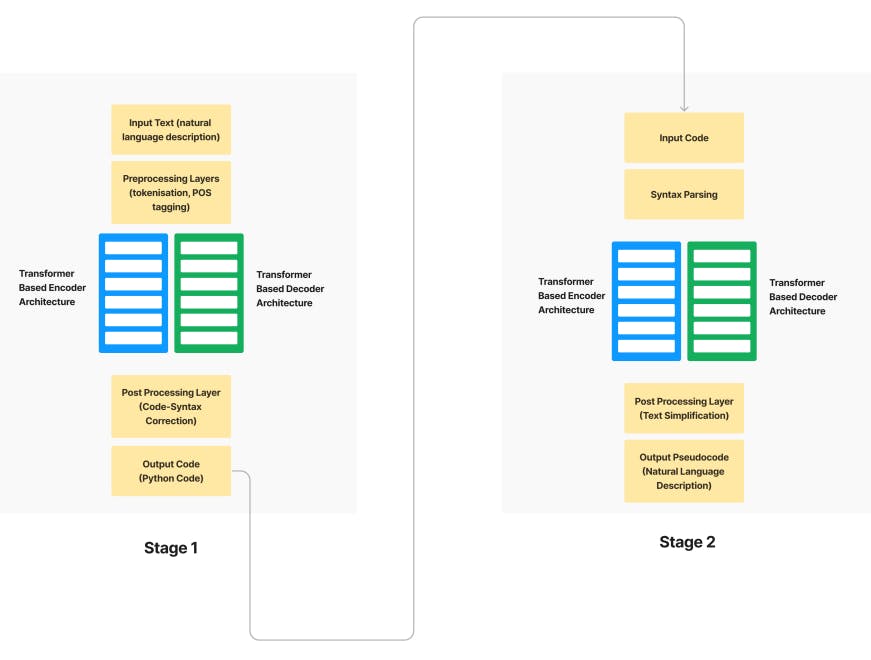
Our research paper aims to generate pseudocode from a given English language prompt. In order to achieve this task, we have divided the workflow into two stages, namely Text to Code Conversion and Code to Pseudocode Conversion. We have fine-tuned CodeT5 Model to get the required output. The performance of the model was measured in the form of BLEU score.
1) Text to Code Conversion: This stage converts the initial Natural Language text input into Python code. Python was chosen as the intermediate representation language due to its common use and availability of datasets on Python code. Text-to-code generation produces program code in a programming language from a natural language description
of a program as its input. An encoder (such as a transformer-based design) creates a set of hidden states from the input text after preprocessing it (for example, tokenization and part-of-speech tagging). The output program code is produced by a decoder (such as an LSTM-based architecture) using these concealed states as input. The final result is then returned after postprocessing (for example, to fix syntax mistakes).
• Input Text (natural language description): This refers to the initial text input that is to be converted into code or pseudocode. This could be a sentence, a paragraph, or a longer piece of text that describes a computational task or problem to be solved.
• Preprocessing Layers (tokenization, POS tagging): This involves preparing the input text for further processing by breaking it down into individual words or symbols (tokenization) and identifying the part of speech of each token (POS tagging). Tokenization is the process of dividing text into meaningful units, or tokens, while POS tagging is the process of labeling each token with its corresponding part of speech, such as noun, verb, adjective, etc.
• Encoder (transformer-based architecture): The encoder takes in the preprocessed text and processes it using a transformer-based architecture, which learns to map the input text to a numerical representation that captures its meaning. The transformer-based architecture is a type of neural network architecture that has achieved state-of-the-art performance in many natural language processing tasks.
• Decoder (transformer-based architecture): The decoder takes in the encoded representation of the input text and generates the corresponding code or pseudocode output. The decoder also uses a transformer-based architecture and is trained to generate code or pseudocode that is consistent with the input text.
• Postprocessing Layers (code syntax correction): This stage involves checking the generated code for syntax errors and correcting them to ensure that it adheres to the syntax rules of the target programming language. This is an important step to ensure that the generated code is syntactically correct and can be executed without errors.
• Output Code (programming language code): This refers to the final output of the text-to-code generation process, which is a block of code written in a programming language. The programming language used for the output code depends on the task or problem being solved.
2) Code to Pseudocode Generation: The Python code generated in stage one is converted to pseudocode form. In code-to-pseudocode generation, a programming language’s programme code serves as the input, and a simplified, high-level description of the code is produced as the output in everyday English. The input code is first preprocessed (for example, by parsing the syntax), and after that it is sent via an encoder (for example, a transformer-based architecture) to produce a set of hidden states. The decoder (also a transformer-based architecture) uses these hidden states as input and produces the output pseudocode. The final result is then postprocessed (for example, to make the text simpler) and returned as the output pseudocode.
Both stages of the proposed approach are analogous to a language translation task. We use an encoder-decoder transformer model to first convert the English text to Python code, and then the Python code to pseudocode.
• Preprocessing Layers (syntax parsing): This stage involves preparing the input code for further processing by breaking it down into its component parts and identifying the relationships between those parts (syntax parsing). Syntax parsing is the process of analyzing the structure of the code and identifying its constituent parts, such as variables, functions, and control structures.
• Encoder (transformer-based architecture): The encoder takes in the parsed code and processes it using a transformer-based architecture to learn a numerical representation that captures its meaning. This encoder is similar to the one used in the text-to-code generation process, but it is trained on code rather than natural language text.
• Decoder (transformer-based architecture): The decoder takes in the encoded representation of the input code and generates the corresponding pseudocode output. This decoder is similar to the one used in the text-to-code generation process, but it is trained to generate pseudocode instead of code.
• Postprocessing Layers (text simplification): This stage involves simplifying the generated pseudocode to make it more easily understandable to humans. This may involve removing redundant or ambiguous information, simplifying complex expressions, or rephrasing complex statements in simpler terms.
• Output Pseudocode (natural language description): This refers to the final output of the code-to-pseudocode generation process, which is a simplified natural language description of the input code. The output pseudocode is designed to be more easily understandable to humans than the original code, and may involve rephrasing complex statements in simpler terms, removing redundant information, and simplifying complex expressions. The pseudocode may be used as a higher-level description of the code, making it easier to understand and maintain.
2) Code to Pseudocode Generation: The Python code generated in stage one is converted to pseudocode form. In code-to-pseudocode generation, a programming language’s programme code serves as the input, and a simplified, high-level description of the code is produced as the output in everyday English. The input code is first preprocessed (for example, by parsing the syntax), and after that it is sent via an encoder (for example, a transformer-based architecture) to produce a set of hidden states. The decoder (also a transformer-based architecture) uses these hidden states as input and produces the output pseudocode. The final result is then postprocessed (for example, to make the text simpler) and returned as the output pseudocode.
Both stages of the proposed approach are analogous to a language translation task. We use an encoder-decoder transformer model to first convert the English text to Python code, and then the Python code to pseudocode.
• Preprocessing Layers (syntax parsing): This stage involves preparing the input code for further processing by breaking it down into its component parts and identifying the relationships between those parts (syntax parsing). Syntax parsing is the process of analyzing the structure of the code and identifying its constituent parts, such as variables, functions, and control structures.
• Encoder (transformer-based architecture): The encoder takes in the parsed code and processes it using a transformer-based architecture to learn a numerical representation that captures its meaning. This encoder is similar to the one used in the text-to-code generation process, but it is trained on code rather than natural language text.
• Decoder (transformer-based architecture): The decoder takes in the encoded representation of the input code and generates the corresponding pseudocode output. This decoder is similar to the one used in the text-to-code generation process, but it is trained to generate pseudocode instead of code.
• Postprocessing Layers (text simplification): This stage involves simplifying the generated pseudocode to make it more easily understandable to humans. This may involve removing redundant or ambiguous information, simplifying complex expressions, or rephrasing complex statements in simpler terms.
• Output Pseudocode (natural language description): This refers to the final output of the code-to-pseudocode generation process, which is a simplified natural language description of the input code. The output pseudocode is designed to be more easily understandable to humans than the original code, and may involve rephrasing complex statements in simpler terms, removing redundant information, and simplifying complex expressions. The pseudocode may be used as a higher-level description of the code, making it easier to understand and maintain.
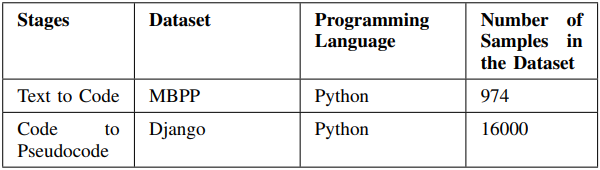
As shown in Table, our research utilized two datasets for the Text to Code and Code to Pseudocode stages. The first dataset, MBPP, consisted of 974 samples and was used for the Text to Code stage. The second dataset, Django, consisted of 16,000 samples and was used for the Code to Pseudocode stage. This table provides important information about the datasets used in our research, including their size and the programming language they were written in.:
B. Transformers
Transformers are attention-based models that don’t use the typical recurrent layers found in encoder-decoder designs, but rather use multi-headed self-attention. Word embeddings from the input sequence are sent to the first encoder.
The data is then transformed and transmitted to the next encoder. The final encoder in the encoder-stack sends its output to every decoder in the stack of decoders. For translation tasks, the Transformer may be trained significantly more quickly than designs based on recurrent or convolutional layers.
The encoder and decoder layers in the Transformer architecture ?? each employ multi-headed self-attention processes as opposed to conventional recurrent or convolutional layers. In order to produce a sequence of context embeddings, the encoder takes in a sequence of input embeddings and processes it through several layers. One token at a time, the decoder creates an output sequence using the context embeddings and a series of target embeddings. The model is tuned during training to reduce the discrepancy between the goal sequence and the anticipated output sequence. The Transformer is ideally suited for jobs that involve comprehending long-range dependencies because of its self-attention mechanism, which enables it to pay attention to various input and output sequences based on their relevance to the present prediction.
C. CodeT5 Model
Modern neural language model CodeT5 was created with the goal of producing excellent source code from natural language inquiries. It is founded on the T5 architecture, which uses a framework for encoders and decoders based on transformers. The model is pre-trained using extensive corpora of natural language and code, which enables it to accurately capture the nuanced relationships between normal language and code. An encoder that handles natural language inputs and a decoder that produces outputs in the form of code make up the architecture of CodeT5. Each token’s contextual representation is produced by the encoder, a multilayer transformer that analyses the incoming text. The decoder, which transforms the encoder’s output into a series of code tokens, is also a multi-layer device. CodeT5 also employs a novel copy mechanism that allows it to directly copy tokens from the input text to the output code, improving the model’s ability to handle rare or out-of-vocabulary words. We train CodeT5 for 40 epochs for the Text to Code conversion task, and for 5 epochs for the Code to Pseudocode conversion task.
D. Rule Based Approach
This method makes use of a Python script to convert python code given to the script as input in the form of a .py file. The Python code given as input is converted into pseudocode with the help of a fixed set of rules.
There are three types of rules:
• Basic conversion rules
• Prefix conversion rules
• Advanced conversion rules
The Python code is scanned line by line and pseudocode is generated for every corresponding set of code. The output of the script is the pseudocode generated in the form of a .txt file
E. Disadvantages of Rule-based approach
The proposed approach is more robust, flexible and dynamically adaptive as compared to the rule-based approach. The scope of the rule-based approach is limited as compared to the extensive scope of our proposed approach. On human evaluation and making use of evaluation metrics like the BLEU score, the proposed approach performs better than the rule based approach. The rule-based approach fails to generate appropriate pseudocode if keywords beyond the scope of the fixed set of conversion rules exist in the code. However, such a case can be appropriately handled by the proposed approach that makes use of transformers. In summary, the proposed approach is more efficient and accurate as compared to the rule-based approach.
This paper is available on arxiv under CC 4.0 license.